YomiComiX とはなんぞや
漫画サイトの漫画を翻訳するブラウザ拡張機能です。現時点では開発中です。
「漫画翻訳」とかでググるとわかるんですが、現状存在する漫画翻訳は多くの場合 Python アプリケーションで、Python 実行して画像を直接指定して変換する工程が必要になります。
例えばこういうのとか:
GitHub に manga-translator のトピックもあります。
これらはどれも品質を高めるためにインペインティングしたり、何回も LLM にかけたりしてる(と思う)のですが、 普段ブラウザで漫画読んでて、わざわざ別のアプリ入れて起動して、画像ファイルを指定して、重い処理を実行して… って往復するのは面倒なので、日常生活で普通に Web 上の漫画を読むときには不便だと思います。 加えて、多くの漫画サイトは簡単には画像ファイルを取得できないようになっていますしね。日常生活だと全然活用できないわけです。
それでも 日本語ローカライズ版が出てない中国語の百合漫画を読みたい! 外国語の漫画を読みたい…! と思ったので、
他のアプリを経由せずに完全にブラウザ上で翻訳が完結するような拡張機能を作ろうと思いました。
イメージとしては、Google 画像翻訳の進化版みたいな感じで、開いてる漫画のページをそのまま開いてるタブのまま、テキストだけ置き換えて表示します。
2025年9月6日に開催された 生成AI何でも展示会 vol.4 でこれの展示を行っていました。
Tip (展示会9月だったけど、なぜ11月になってようやく記事書いてるの?)
単にめちゃくちゃやる気が出なかっただけです。9月から11月にかけて進捗はほぼゼロで、展示会あたりから大きな進展はありません。
Note (「YomiComiX」という名前の由来について)
名前の由来
今回は珍しく名前が決まるのがかなり遅くて、展示会の二日〜三日前くらいに決まりました。
(普段の開発は名前が決まってから開発し始めるくらいのがほとんどだった)。
開発当初の方は単に manga-translator とか呼んでいました。
Gemini に名前の案を相談したところ、出してくれた案の半分くらいは微妙だったんですが意外と日本語読みを考慮した名前の案も結構出してくれて、その中で、
- ComiYomi (コミヨミ): 「Comic」と日本語の「読み」を組み合わせた造語です。漫画を読むためのツールであることが直感的に伝わります。シンプルで覚えやすい点が特徴です。
と言ってて、これは語感も良く、読み間違えづらく覚えやすそうなので、とりあえずひっくり返した YomiComi (ヨミコミ) としました。
「読み」と「コミック」が合わさってるのと、「読み込み」とも掛かっててちょっと面白い。
そのあとで、CRXJS が Chrome Extension JS だったり、WXT が Web Extension の略だったりと、
X が Extension の意味で使えそうだったので X をくっつけて YomiComiX にしたところ、
ComiX で「コミックス」と読めることに気づいて感動したので、最終的に YomiComiX (ヨミコミックス) になりました。
これは展示会の前日くらいに気づきました。
機能
展示会のスライドをもとに説明します:
- 展示会のときのスライド: https://link.p1at.dev/yomicomix
実行例
先にスライド中の実行例を紹介するとこんな感じです。どちらもウェブトゥーンの縦読み漫画の一部を使っています。

「翻訳前」が元の表示で、「翻訳後」は実際に拡張機能を用いて翻訳した後の表示です。 これはだいぶうまく行ってる例になるんですが、テキストの内容も合っていて、背景色や間隔もあんまり問題ない感じで表示されています。
↑の画像は漫画部分だけ切り取ってるのですが、実際のブラウザでの表示は以下のようになります。左が元の表示で、右が拡張機能で翻訳した後の表示です。:
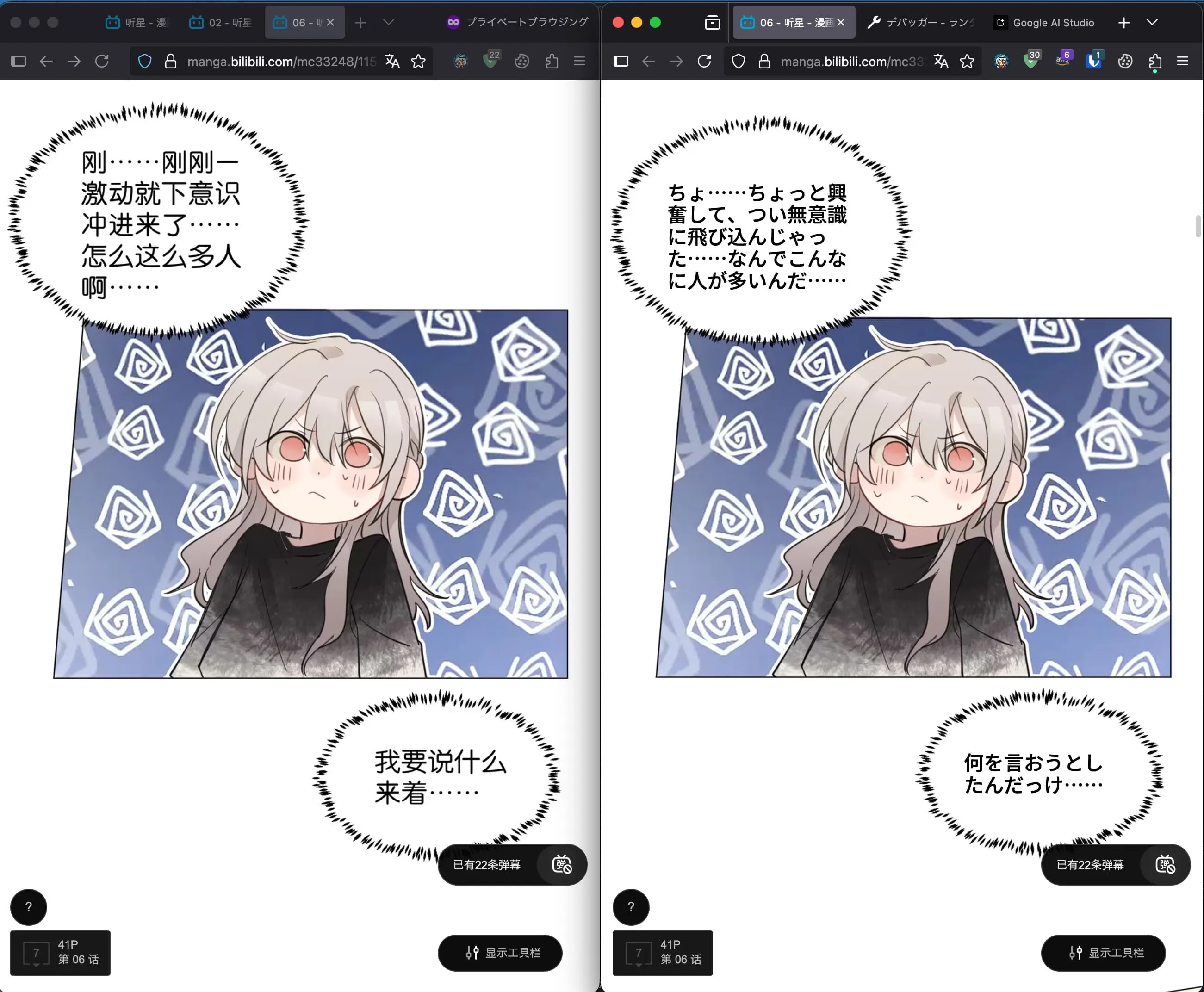
スクショの中の漫画: 听星 06話
全く同じ URL のサイトを開いているんですが、拡張機能によって漫画の文字だけが翻訳されています。 右下や左下の UI は触ってないのでそのままになっているのがわかると思います。
処理の流れ
裏側でどういう処理をやっているのか説明する前に、そもそも漫画の翻訳を実現するとしたら最低限以下のような処理をすることになると思います。
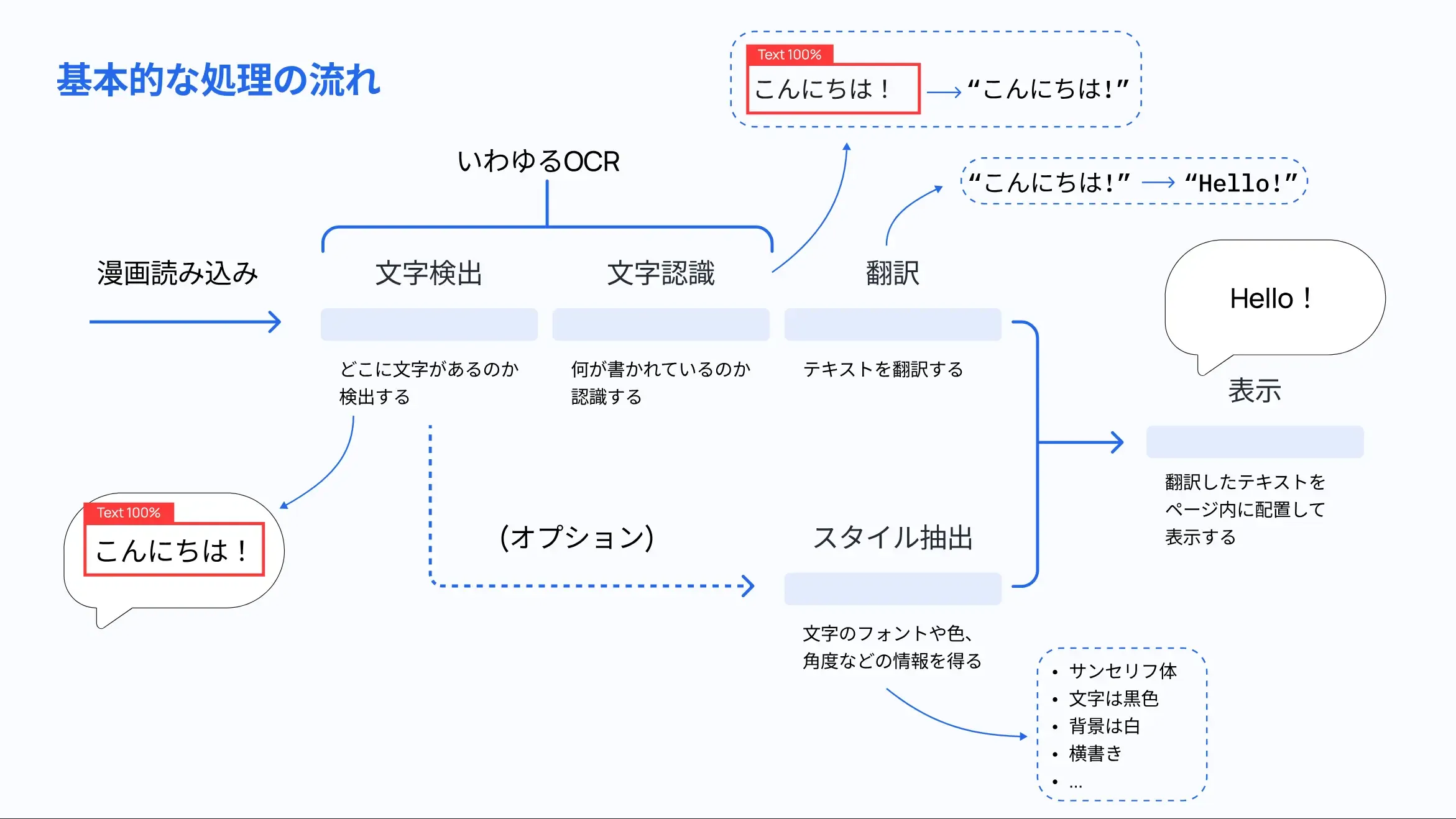
どこかの資料を参照したわけじゃないので、自分が勝手に考えてるだけなのですが、 大きくはずれてないと思います。さらに処理のクオリティを上げる場合は Stable Diffusion やら Lama やらを用いて、 元のテキストを消しゴムマジックしてから「表示」処理を行うかもしれません。
ここで、YomiComiX では以下のようにやっています。
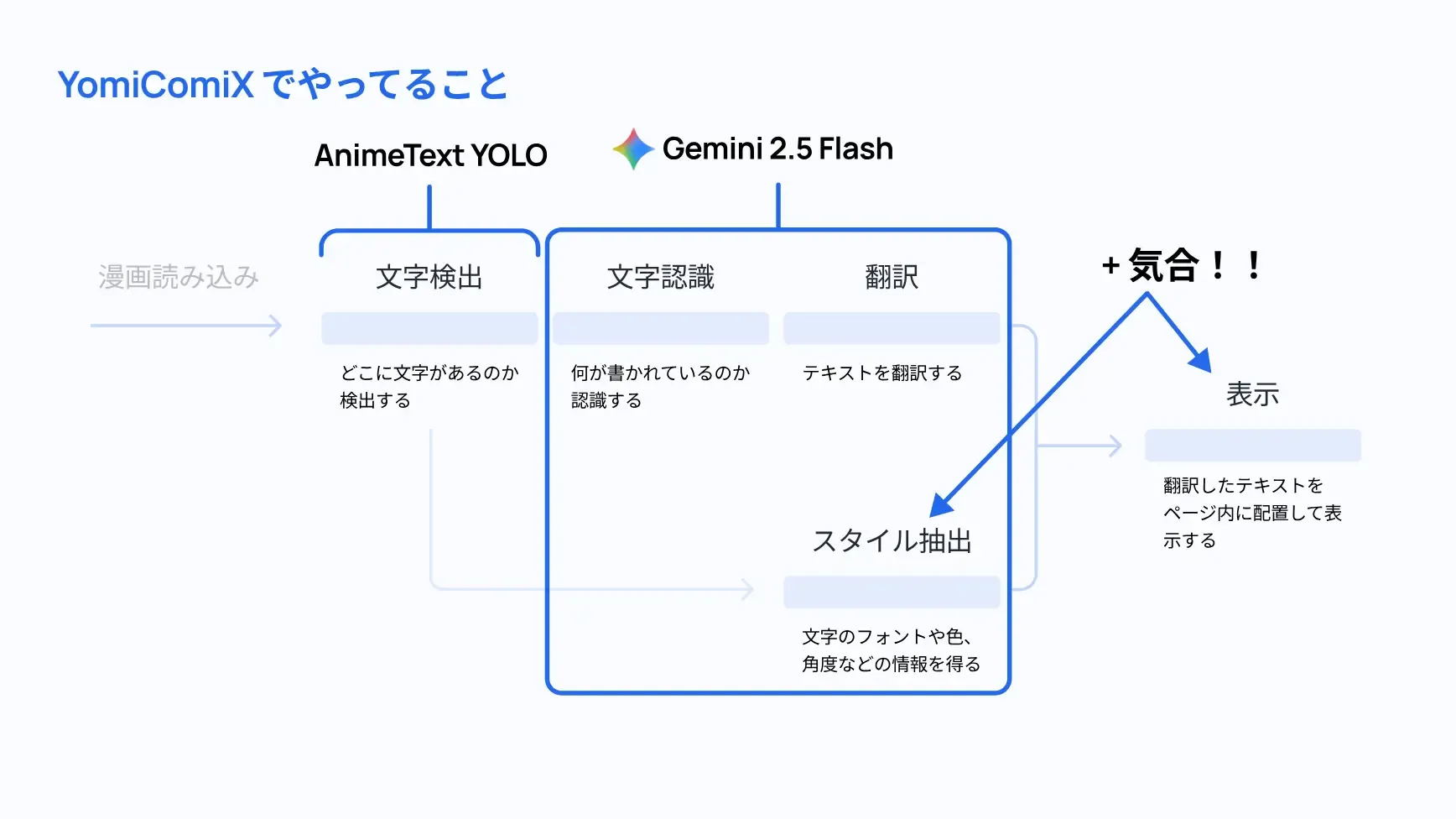
文字検出は AnimeText YOLO、文字認識・翻訳・スタイル抽出は Gemini 2.5 Flash でやっています。 展示会にて、「スタイル抽出と表示が気合なのはなんでなんですか」とめっちゃ聞かれたのですが、 処理の一部か全部がそういう AI モデルに頼らずに地道なプログラムでやっていたりするという理由です。
例えば、文章が横書きか縦書きかを判定するのには、検出したテキストエリアが横長の長方形か縦長の長方形かで判定していたり、 背景色はテキストエリアの周辺の平均を取ってみたり、みたいな感じでやっています。 ちなみに、「テキストエリアが縦長なら縦書き」は9割くらい当たるので、処理コストの割にはかなり効きますw 一方で背景色の判定はだいぶ手こずっている…
全てを Gemini 2.5 Flash に任せようとするとタスクが増えすぎて翻訳が適当になる感じがあったので、 ある程度は自前でやるようにしている感じです。見栄えに直結するので重要ですが、そんなにAI任せできないので一番辛い部分だと思います。
テキスト検出: AnimeText YOLO
以下のモデルを使っています。
deepghs が開発したモデルで、漫画やイラスト内のテキストを検出するのに特化しています。多言語対応で、英語、中国語、日本語、韓国語、ロシア語に対応しているそう。 漫画やイラスト内のテキスト検出性能で言えば、どの OCR モデルよりも性能がいいと思います。PaddleOCR よりも良いです。
HuggingFace Spaces のデモがあるので、軽く試したい場合はこれを触ってみると良さそうです。
これを TypeScript で動かすサンプルコードを以下で公開しています。
拡張機能でも大体上記のレポと同じようなコードでテキストエリアを検出したりアノテーションしたりしています。とにかく軽く動くので非常に良いです。
このモデルの存在が先にあって、このモデルを使って何かできることを探していた点もあるくらいなので、ちょうど今回の拡張機能で採用できて良かったです。
テキスト認識・翻訳・スタイル抽出: Gemini 2.5 Flash
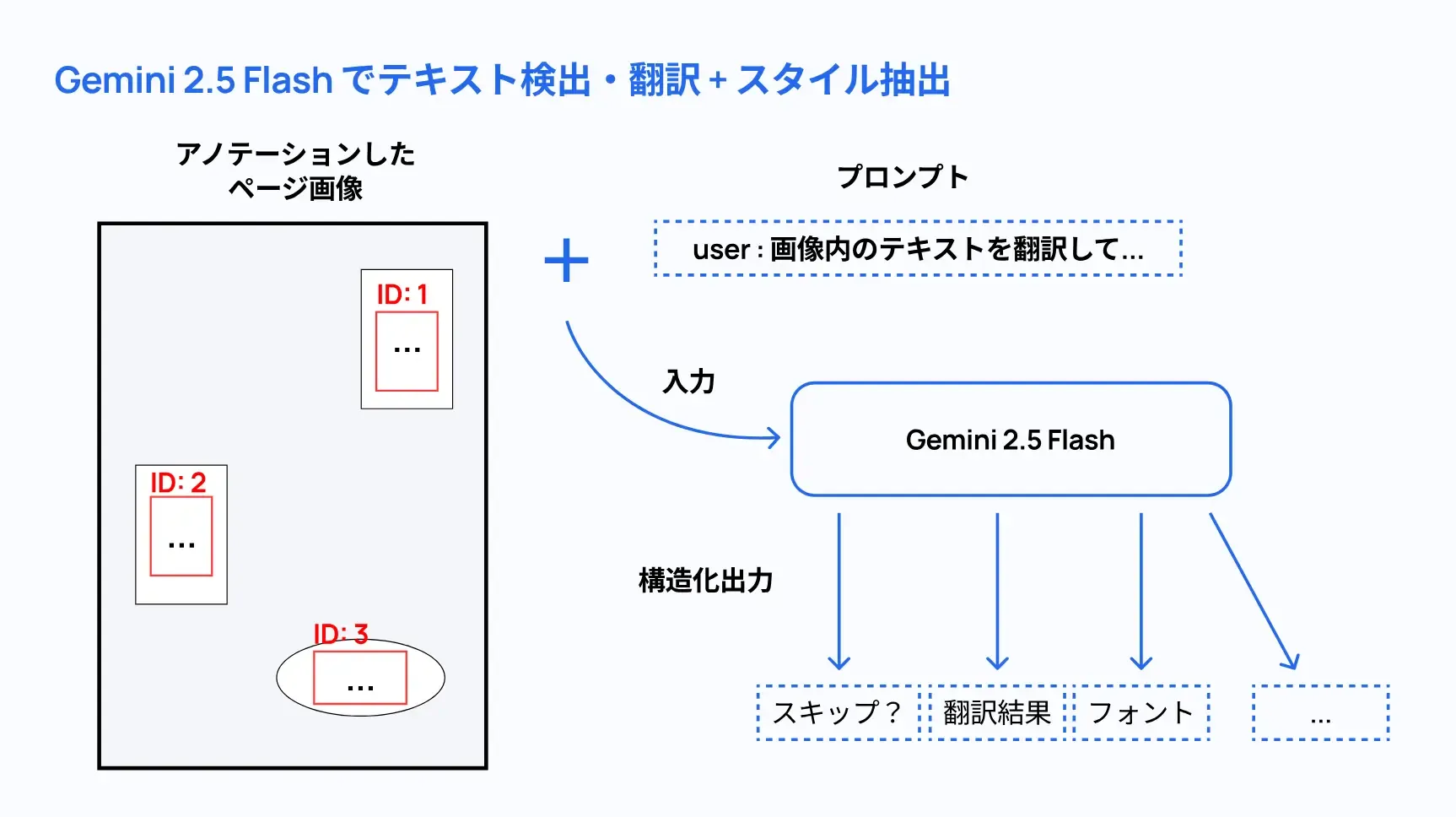
AnimeText YOLO でアノテーションしたページとプロンプトをそのまま Gemini 2.5 Flash に入力として与えて、 JSON 出力機能を用いて、構造化されたデータを得ています。この時、翻訳内容だけでなく、
- そもそも翻訳するかどうか (文字以外を誤認識したり「…」や「!?」みたいな翻訳不要なケースがあるので、この場合に翻訳をスキップするできるようにしている)
- 原文の読み取り結果 (実は案外誤字が多かったりするけど、翻訳を考える補助になるかと思って入れてる。後ろの処理では使ってない)
- テキストの色 (背景色と違って手動で判定するのがむずそうだったので、ここで回答させて実装を楽してる。)
- フォント種類 (現時点だと、
sans-serif,serif,handwritingだけ選ばせている)
を回答させています。フォント種類の判定は想像以上にうまくいっていて、手書き風テキストはこれだけでかなり見栄えが良くなりました。
テキスト認識だけは OCR モデルだけ用意したら手元でもできそうな気がしたんですが、認識精度が確保できなかったので諦めました。 PaddleOCR のデモしか試してなかったんですが、漫画内のテキストを全然うまく検出できなかったんですよね。 仮に検出できても、正しく文字を認識できなかったり、縦読みや横読みを間違えたりすることがあって、全然信頼できなかったので使わなかったです。
結局、全部 Gemini に丸投げした方がスマートに行く感じでした。
表示処理
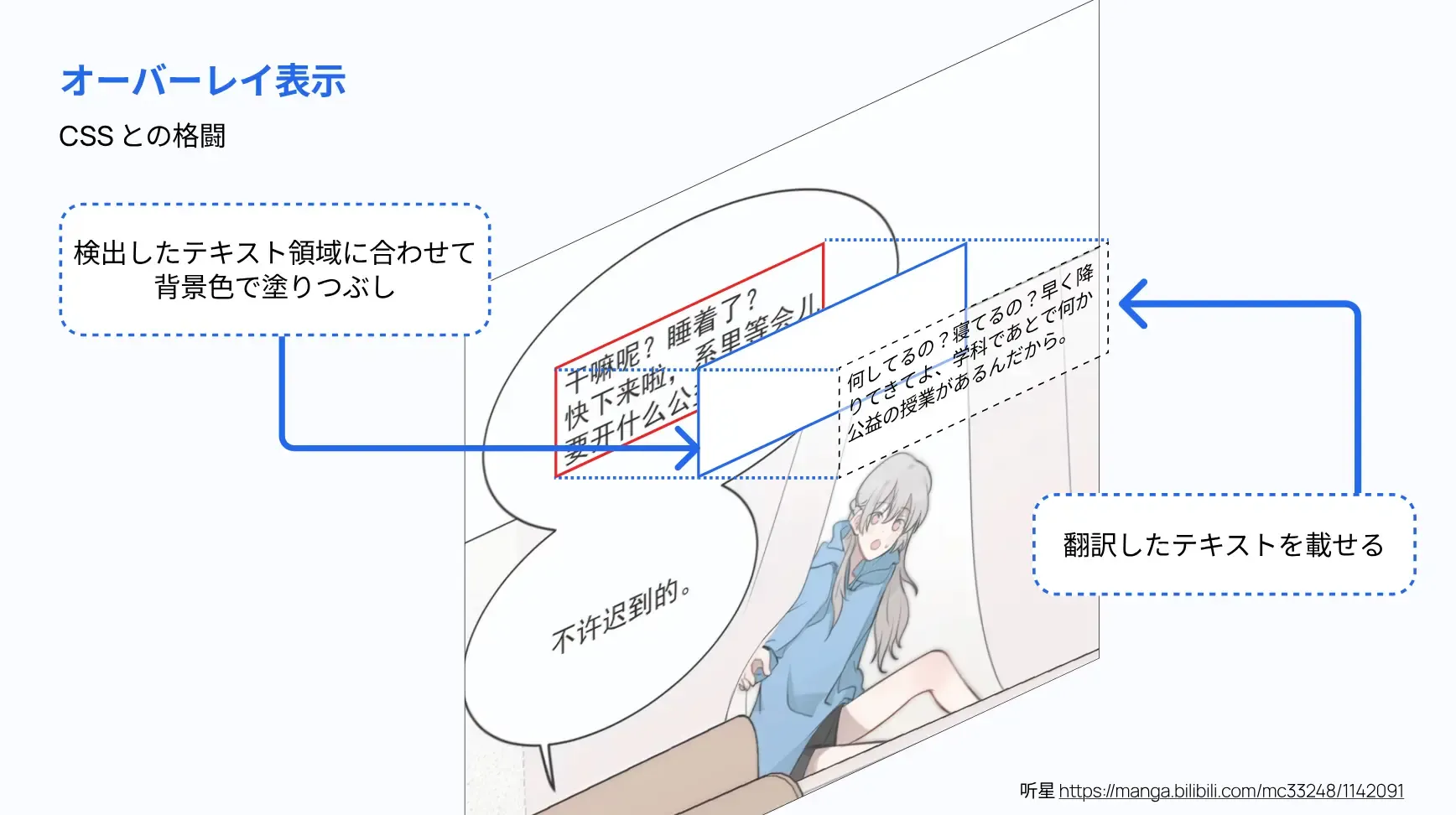
テキストの翻訳まで完了したらあとは表示するだけです。と言っても、言葉で説明する以上に面倒な処理です。 ここは実際の実装だと一番大変な部分なんですが、一番存在を感じられない箇所でもあるので、実装の苦労が伝わりづらい部分でもあります。 存在に気づかれないということは自然にできているということでもあるので、それはそれで良いことではあります。
大変になっている理由として、**「画像に直接書き込まずに HTML 要素で実現したい」**というこだわりがあるからなんですが、 この縛りを入れると急に難易度が爆上がりします。これには以下のような理由があります:
- HTML が 動的に変化する 可能性がある
- 動的に変化しても、Web アプリはうちの拡張機能のことは考慮しないので、オーバーレイを表示するための要素が消える可能性がある
- CSS が相互に影響を受ける可能性がある
- オーバーレイする場合は、そのオーバーレイ要素や表示するテキストのスタイルを CSS で設定しないといけないが、 この時の CSS が元ページの CSS と相互に干渉する可能性がある (特に TailwindCSS!)。気をつけないといけない。
- テキストの正解スタイルが不明
- どのようにテキストを配置すると最も自然になるかが不明瞭なまま配置する必要がある。 特に、テキストの配置されている範囲はわかるものの、文字や吹き出しそのもののサイズや形状は不明だったり、 吹き出しじゃないテキストの可能性もあるため、表示に適するテキストサイズや横幅などが不明瞭。
動的な HTML の問題はサイトごとに対応するしかないです。展示会時点では bilibili 漫画にしか対応してなかったのですが、これが理由です。
少年ジャンプ+ などの GigaViewer タイプや、
カドコミ (旧コミックウォーカー) も対応しようかと思ったのですが、
どちらも漫画ページの切り替わりで頻繁に DOM が変化するので対応難易度が高く、時間もなかったので対応を見送りました。
カドコミは特に、レスポンシブ対応で画面幅が切り替わるたびに新しいコンポーネントが生成されるため、レスポンシブを考慮するとむちゃくちゃ難しいと思います。
div.splide を監視しながらブラウザの横幅を変えると id がどんどんインクリメントされていくのが見れます。やべ〜
CSS の問題は TailwindCSS を使いたい時に厄介で、リセット CSS や同名のクラス名が干渉してしまうんですよね。 なので、最終的にはプレフィックス機能を使って干渉しないようにしました。 少しクラスが冗長になってしまうんですが、干渉して元サイトが崩れるよりはマシなので妥協しました。 こういう時のために Shadow DOM がある?らしいので、使ってみたいと思ったのですが、 スタイルの適用範囲だったり挙動が非直感的で全然思った通りに操作できず、 結局普通の DOM 操作 (React をマウントしてる) になりました… Shadow DOM 全然わからん…
最後の、正解スタイルが不明なことについてですが、テキスト検出時点から吹き出しや周囲の情報を得られないので、 テキストを配置した時に違和感なく自然に配置するのが難しいです。あんまりいい方法が思いついてないので、 とりあえず全部少し小さめのフォントサイズに統一して表示することにしています。 おそらく、検出されたテキストエリアのサイズと翻訳前後の文字数を考慮して文字サイズを調整すればいいのかもしれないんですが、 具体的にどうするか思いついてないので、今後どうにかします。
目指すところ
ブラウザから離れたアプリを実行するくらいなら、めちゃくちゃ手軽な OCR ソフトにかけて、 適当な翻訳機にかけた方が、読むスピードは速いと思います。 単に翻訳するだけの Python スクリプト作っても処理に時間がかかるだけで、そこまで便利にならないはずです。
なので、なるべく手を動かさずに漫画を読むためには、ブラウザ拡張の形で実現するのが良いと考えました。 漫画のページを開くだけで勝手に翻訳されて、しかもそれっぽい見た目で表示されてくれれば、かなり楽に漫画を読めそう〜
個人的にこういう点を大事にしたいです:
- 手軽さ
- 先述したような、手動で翻訳元言語を設定するみたいな操作を挟みたくない。可能であればノーコンフィグで動作するのが理想的。
- 高い API 代は払いたくない。無料の翻訳ツールの組み合わせの代替なので、あんまり高いと意味がないし、それなら既存サービスを頼った方が良さそう。
- けど、上限はあるのである程度の出費は致し方なしか…? 低コストのサブスクにでもできればいいけど、黒字にするのはまた別で難しそうな問題
- 動作コストの低さ
- ブラウザ拡張なので、ローカルで行う処理はそこまで重いことはできないし、したくない
- 処理速度
- 早く読みたいので、そんなに長い時間待てない〜
- 見た目の良さ
- 翻訳結果の見た目が良くないとちょっとテンション下がる
手軽さは本当に重要で、ローカルで Python サーバーを立ち上げて拡張機能で叩く… みたいなのは論外。拡張機能を入れて、それだけで動作してくれれば最高です。 楽するために作ってるんだから楽になってもらわないと困る🥺…
処理を増やしたりかける時間をかければ見た目のクオリティは上げられると思うのですが、 翻訳終わるまでに数分かかってるようだと全然サクサク読めなくて辛いので、 速度とクオリティをトレードオフしてでも、読める最低限の品質をすぐに提供できるようになるといいなと思います。
大体こういう感じの方針でやっていきたいと思います。 ただ、既に自分にとってめちゃくちゃ役に立ってるので、インターフェースを整えれば他の人も使えるかな…と思いつつも、 自分が既に需要を満たしてしまっているからこれ以上労力をかけたくないジレンマがあります…
実際の使用感(別記事で)
実際にこの拡張機能を使って100話くらい読むことができたので、その漫画の感想と一緒に拡張機能の感想も書こうと思います。